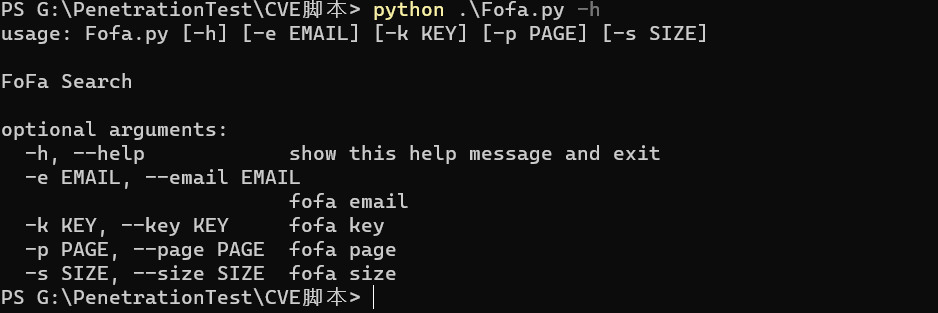
前言
周末在家闲来无事,想着学习一下如何使用python进行fofa查询,本篇文章仅作为学习过程中的记录。
网页搜索
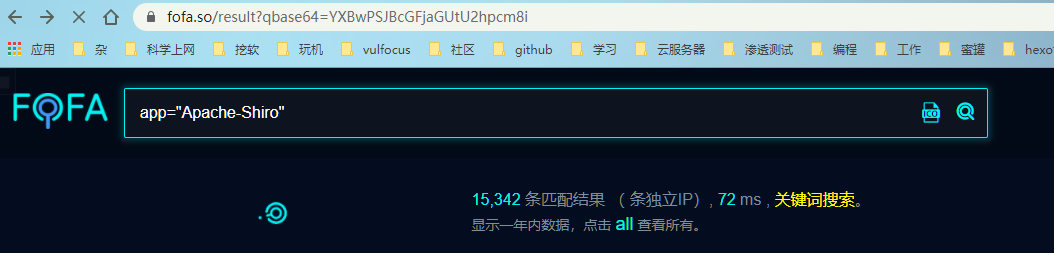
注意看查询的链接:
1
| https://fofa.so/result?qbase64=YXBwPSJBcGFjaGUtU2hpcm8i
|
也就是说查询的语句经过base64编码拼接在后面,但是这样搜索之后是整个页面,而需要的只是IP链接这里,所以用到了fofa的API功能
1
| https://fofa.so/api/v1/info/my?email=${FOFA_EMAIL}&key=${FOFA_KEY}
|

1
| https://fofa.so/api/v1/search/all?email=${FOFA_EMAIL}&key=${FOFA_KEY}&qbase64={}
|
第一个是认证email和key的准确性,第二个是查询接口,再根据接口的返回信息确认准确性。
1
2
3
4
| {
"error": true,
"errmsg": "401 Unauthorized, make sure email and apikey is correct."
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| {
"mode": "extended",
"error": false,
"query": "domain=\"nosec.org\"\n",
"page": 1,
"size": 6,
"results": [
[
"https://i.nosec.org"
],
[
"https://nosec.org"
],
[
"down3.nosec.org"
],
[
"www.nosec.org"
],
[
"nosec.org"
],
[
"cdn.nosec.org"
]
]
}
}
|
这时利用查询接口的API进行查询:
1
| https://fofa.so/api/v1/search/all?email=email&key=key&qbase64=YXBwPSJBcGFjaGUtU2hpcm8i
|
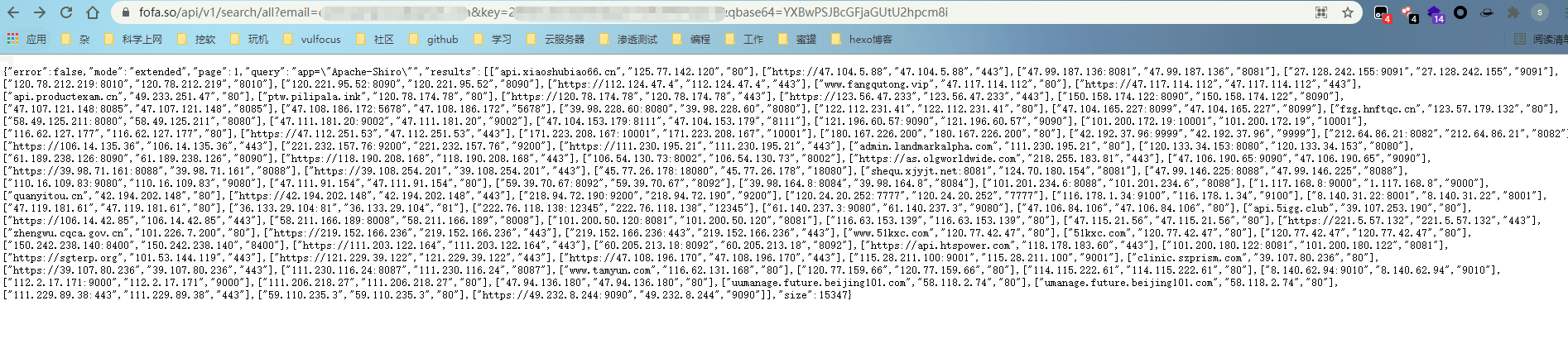
大大简化了数据的复杂性,接下来就是将ip从results里面取出来。
编程实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| # /usr/bin/ python
# author givemefivw
# data 2021-08-01
import requests
import json
import argparse
import base64
import codecs
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='FoFa Search')
parser.add_argument('-e','--email',help='fofa email',default='')
parser.add_argument('-k','--key',help='fofa key',default='')
args = parser.parse_args()
email = args.email
key = args.key
fofa_url = "https://fofa.so/api/v1/info/my?email=" + email + "&key=" + key
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded"
}
res = requests.get(fofa_url, headers=header)
if email != None and key != None:
if 'errmsg' not in res.text:
print("[+] FoFa接口认证成功")
else:
print("[-] FoFa接口认证失败,请检查KEY值")
fofa_search = 'app="Apache-Shiro"'
sentence = base64.b64encode(fofa_search.encode('utf-8')).decode("utf-8")
#print(sentence)
fofa_search_url = "https://fofa.so/api/v1/search/all?email=" + email + "&key=" + key + "&qbase64=" + sentence
res = requests.get(fofa_search_url, headers=header)
if 'errmsg' not in res.text:
result = json.loads(res.text)
for link in result['results']:
print(link[0])
else:
print("[-] 查询失败,请检查fofa语句或key值")
|
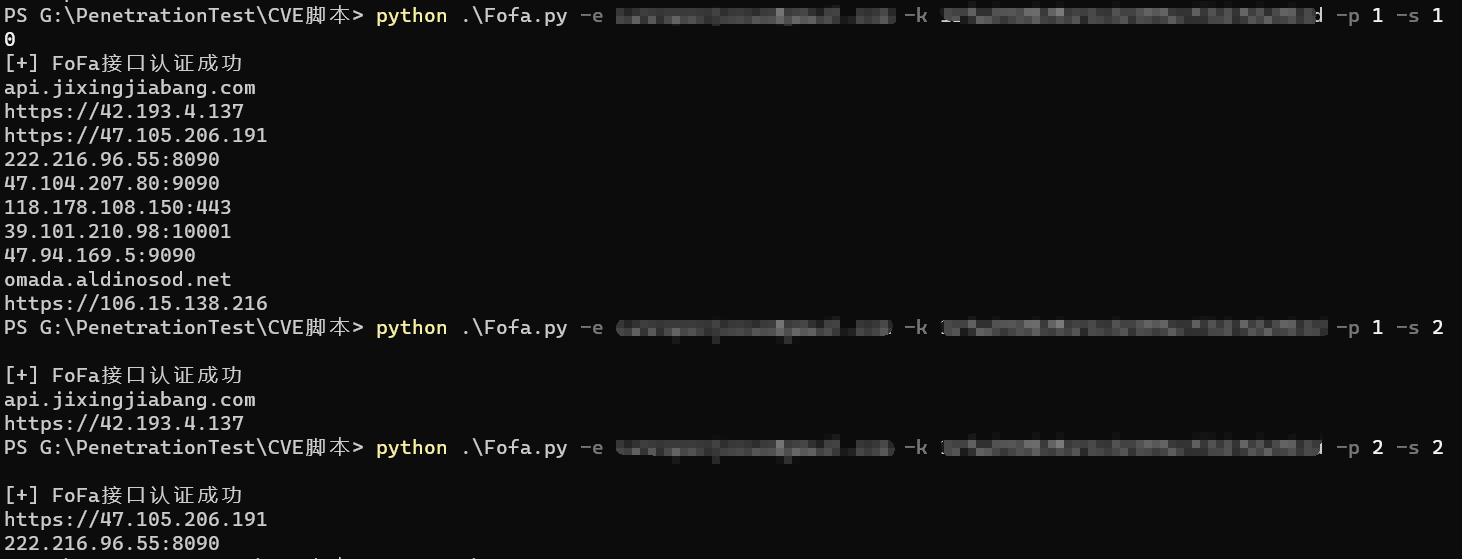
看下运行效果:
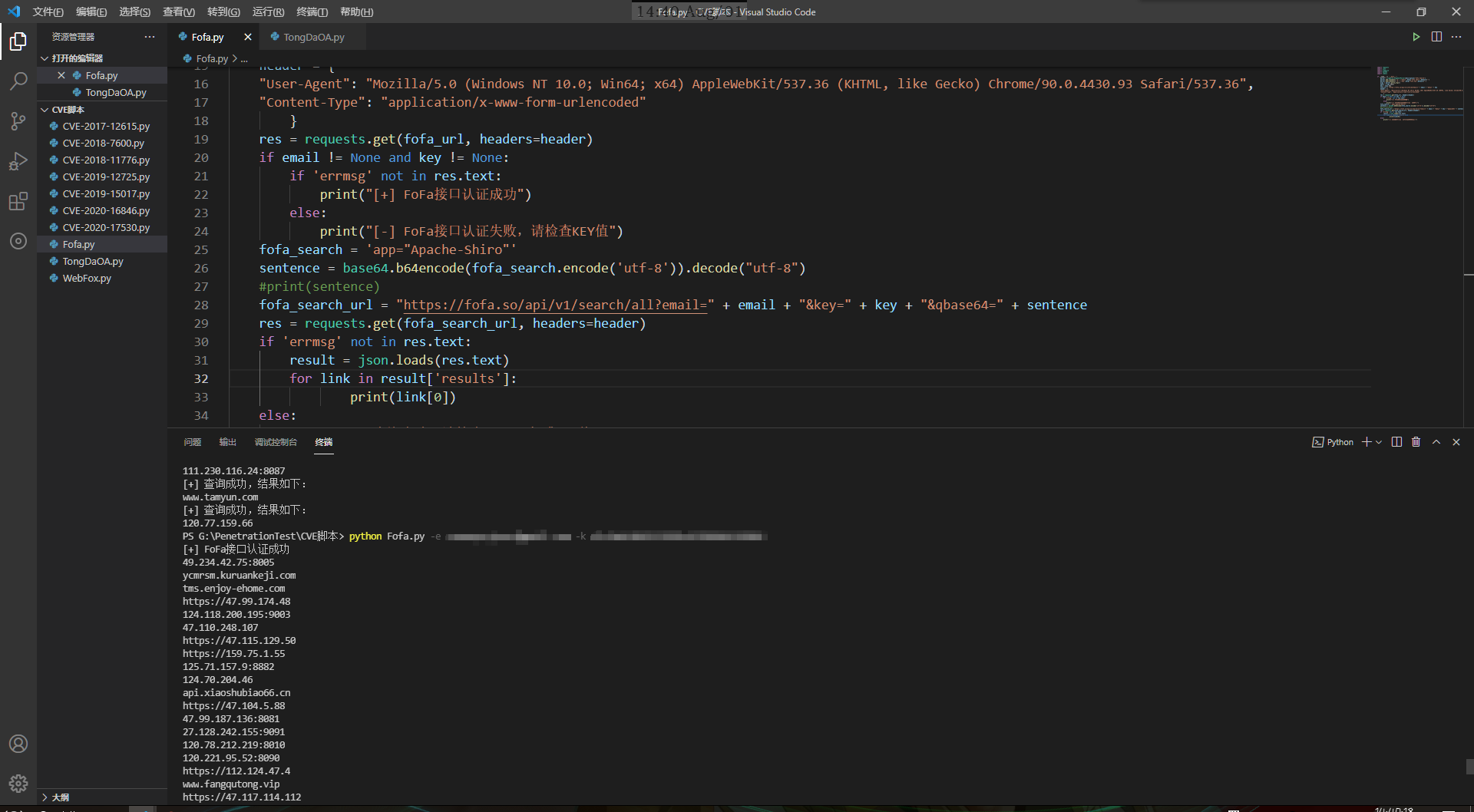
收集到IP和网址之后,就可以进行批量查询利用啦~
进阶调用
查询到100个结果之后,又想可不可以指定查询的页码和查询的数据量呢?
再次查看Fofa网站的API说明文档,发现查询接口有如下几个参数:

根据说明可以得知,查询时常用的参数有三个:qbase64,page、size
那么根据参数qbase64的查询方式,不难得出,只需要在后面拼接其余两个参数就可以达到目的效果。
1
| https://fofa.so/api/v1/search/all?email=email&key=key&qbase64=YXBwPSJBcGFjaGUtU2hpcm8i&page=1
|
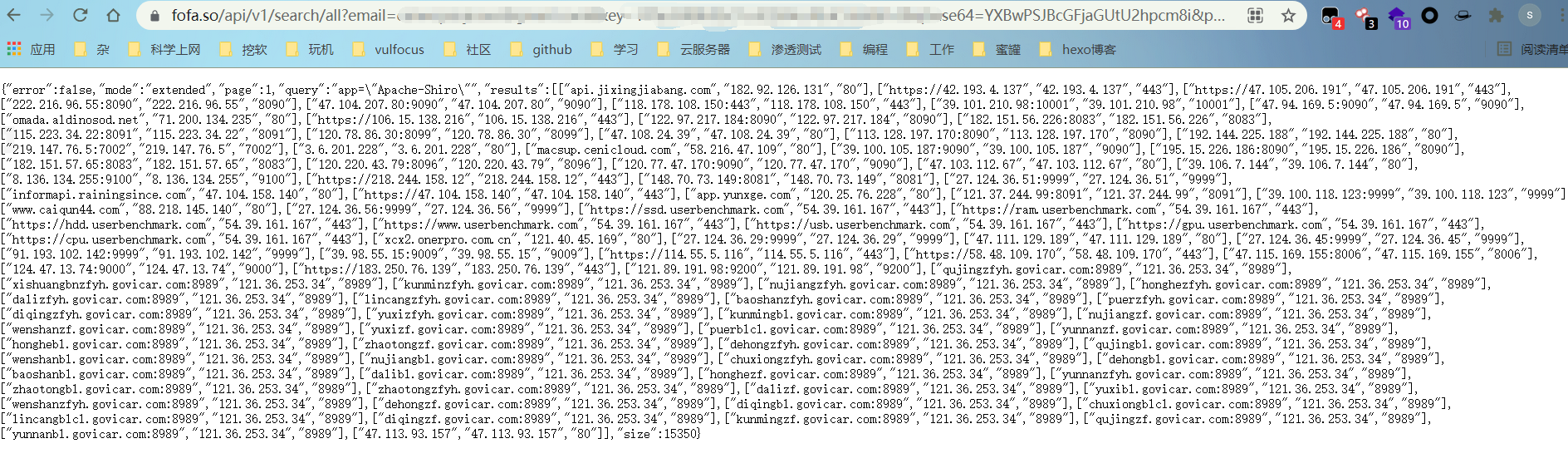

如此,达到了指定页码的问题。
第二个效果,指定查询的数据量,通过size参数来实现。
1
| https://fofa.so/api/v1/search/all?email=email&key=key&qbase64=YXBwPSJBcGFjaGUtU2hpcm8i&page=1&size=200
|
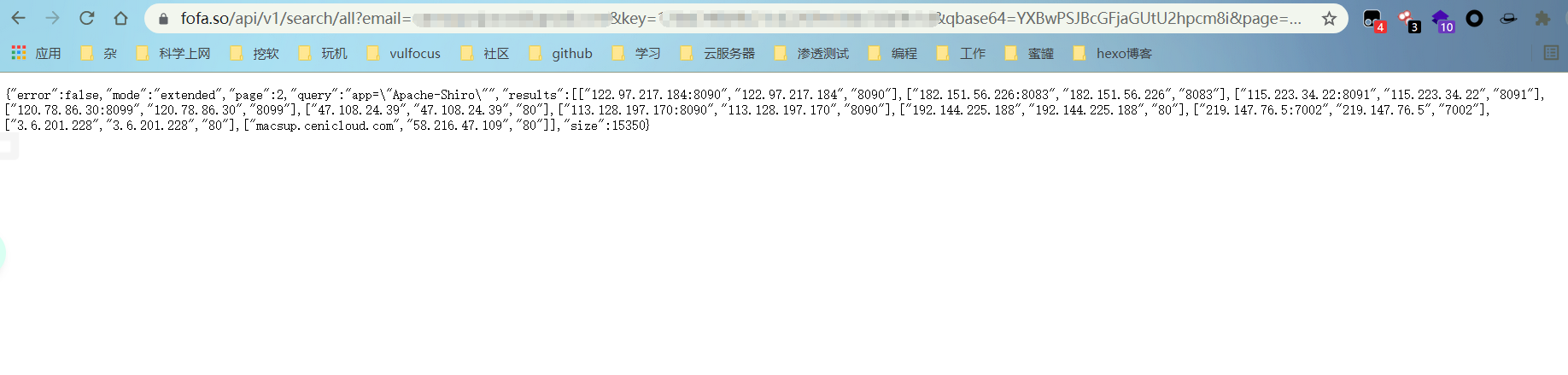
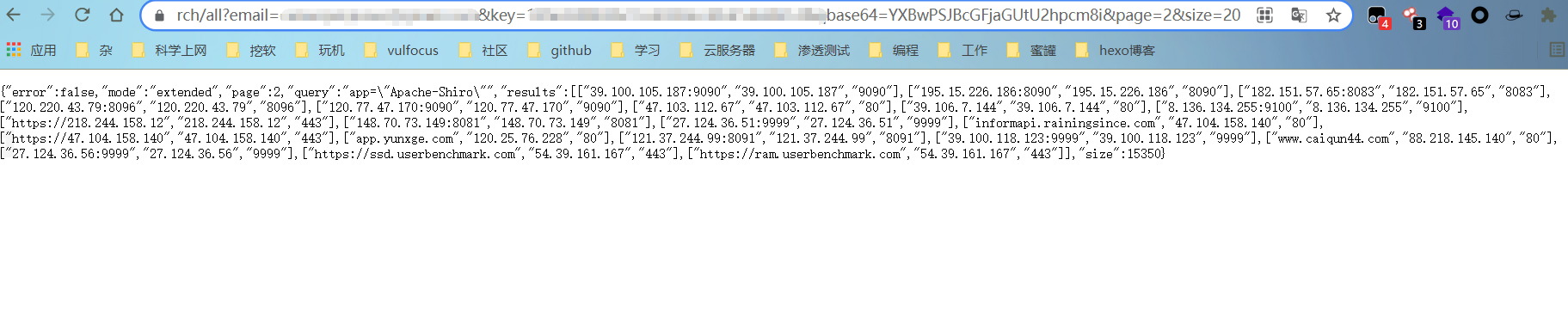
如此,指定查询的数量也实现了,参数之间还可以搭配使用。
脚本修改如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| import requests
import json
import argparse
import base64
import codecs
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='FoFa Search')
parser.add_argument('-e','--email',help='fofa email',default='')
parser.add_argument('-k','--key',help='fofa key',default='')
parser.add_argument('-p','--page',help='fofa page',default='1')
parser.add_argument('-s','--size',help='fofa size',default='100')
args = parser.parse_args()
email = args.email
key = args.key
page = args.page
size = args.size
fofa_url = "https://fofa.so/api/v1/info/my?email={}&key={}".format(email,key)
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded"
}
res = requests.get(fofa_url, headers=header)
if email != None and key != None:
if 'errmsg' not in res.text:
print("[+] FoFa接口认证成功")
else:
print("[-] FoFa接口认证失败,请检查KEY值")
fofa_search = 'app="Apache-Shiro"'
sentence = base64.b64encode(fofa_search.encode('utf-8')).decode("utf-8")
#print(sentence)
fofa_search_url = "https://fofa.so/api/v1/search/all?email={}&key={}&qbase64={}&page={}&size={}".format(email,key,sentence,page,size)
res = requests.get(fofa_search_url, headers=header)
if 'errmsg' not in res.text:
result = json.loads(res.text)
for link in result['results']:
print(link[0])
else:
print("[-] 查询失败,请检查fofa语句或key值")
|